Кто такой data scientist?
Содержание:
- Как стать специалистом – об образовании
- Зарплата data scientist
- Стажировка для аналитиков
- Data Scientist: кто это и что он делает
- Проанализируем данные
- Дата-сайентисты в облаках
- Направления
- Какие специалисты работают с данными
- Будущее Data Science
- «Самая сексуальная профессия»
- Достоинства и недостатки профессии
- Следующий шаг — полировка и углубление знаний
- Кто он, Data Scientist?
- Кто такой Data Scientist?
Как стать специалистом – об образовании
Теперь понятно, что такое Data Science (перевод этого термина), а также чем занимается соответствующий работник. Но возникает вопрос о том, каким образом начать карьеру в этой области.
ВУЗы в России пока не предлагают подобный курс. Зато можно обучиться на IT-специалиста, а затем заняться самообразованием. Но лучшее решение – это специализированные курсы. Их организовывают образовательные центры.
Посещать лекции можно как дистанционно, так и очно. Срок обучения – от нескольких месяцев до года. В результате человек сможет изучить выбранное направление науке об анализировании сведений, а также подтвердит его сертификатом установленной формы.
Зарплата data scientist
Доходы зависят от опыта, объема работы и региона. Зарплата специалистов по обработке данных в России, согласно информации HeadHunter, достигает 8,5–9 тыс. долларов (543–575 тыс. рублей) в месяц с учетом бонусов.
Data scientist должен иметь обширные знания в разных областях
В США такие сотрудники зарабатывают 110–140 тыс. долларов (7–9 млн рублей) в год, то есть в месяц около 9–11 тыс. долларов (575–703 тыс. рублей).
Сколько получает junior data scientist
Исследовательский центр HR-портала SuperJob приводит более приземленные цифры. Начинающий специалист в Москве, согласно статистике, может рассчитывать на стартовый оклад от 70 тыс. рублей, в Санкт-Петербурге — 57 тыс. рублей. По мере накопления опыта (до 3-х лет) зарплата увеличивается до 110 тыс. рублей в столице и 90 тыс. рублей в Питере.
Зарплаты опытных специалистов
Эксперты SuperJob выяснили, что профессиональный эксперт-аналитик с научными публикациями в Москве зарабатывает около 220 тыс. рублей в месяц, в Санкт-Петербурге — 180 тыс. рублей. По информации JetBrains, ведущего мирового производителя инструментов для работы с современными технологиями, старший специалист по анализу данных в среднем получает 186 тыс. рублей в месяц.
Что нужно знать о data scientist — рассказывает специалист:
В основе data science лежат простые идеи, но на практике обнаруживается множество тонкостей. Поэтому квалифицированные специалисты — это ценные кадры. Но реальная потребность имеется в сотрудниках уровня middle и выше.
Стажировка для аналитиков
У специалистов, заинтересованных в аналитике и машинном обучении есть возможность получить необходимы для карьерного роста знания. Для этого существует так называемая стажировка. Она носит названием SAS.
Включает в себя:
- компьютерную лингвистику;
- майнинг;
- разработку процессов интеграционного типа на SAS и Open Source;
- потоковую обработку информации;
- кластеризацию;
- визуализацию;
- составление прогнозов;
- исследование информации;
- участие в проектах майнинга;
- back-end;
- front-end;
- создание предсказательных математических моделей.
Для того, чтобы Data Science-специалист прошел соответствующую практику по аналитике данных, потребуется компьютер и доступ в интернет. Алгоритм действий будет следующим:
- Подать заявку в электронном виде. Принимаются студенты бакалавриата (3-4 курс), а также магистратуры.
- Пройти тестирование. Это делается дистанционно.
- Обучаться согласно установленной программе.
- Пройти собеседование и итоговое тестирование.
Пользователям, прошедшим обучение в Москве и других регионах, предоставляется помощь при трудоустройстве после успешного завершения стажировки SAS.
Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Более 100 крутых уроков, тестов и тренажеров для развития мозга
Начать развиваться
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.
Проанализируем данные
Вернемся к нашему примеру. На глаз кажется, что два параметра как-то взаимосвязаны: чем меньше человек спал, тем больше он выпьет кофе на следующий день. При этом у нас есть и выбивающийся из этой тенденции пример – любительница поспать и попить кофе Полина. Тем не менее можно попытаться приблизить полученную закономерность некоторой общей прямой линией так, чтобы она максимально близко подходила ко всем точкам:
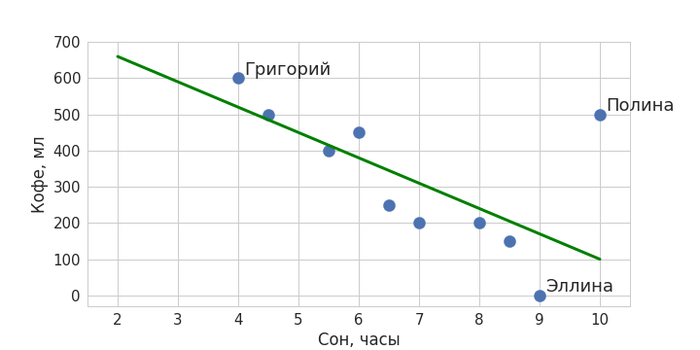
Зеленая линия – и есть наша модель машинного обучения, она обобщает данные и ее можно описать математически. Теперь с помощью нее мы можем определять значения для новых объектов: когда мы захотим предсказать, сколько кофе сегодня выпьет вошедший в кабинет Никита, мы поинтересуемся, сколько он спал. Получив в качестве ответа значение в 7,5 часов, подставим его в модель – ему соответствует количество выпитого кофе в объеме чуть менее 300 мл. Красная точка обозначает наше предсказание.
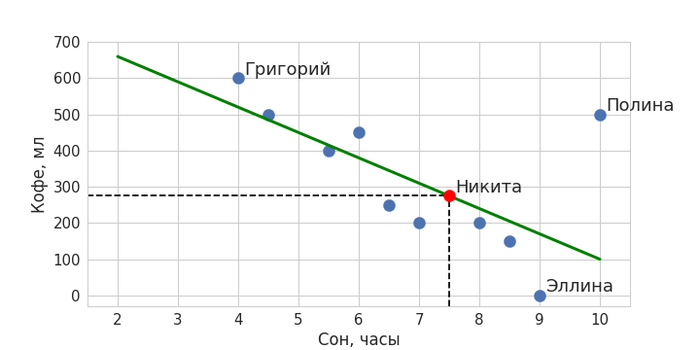
Примерно так и работает машинное обучение, идея которого очень проста: найти закономерность и распространить ее на новые данные. На самом деле, в машинном обучении выделяется еще один класс задач, когда нужно не предсказывать какие-то значения, как в нашем примере, а разбивать данные на некоторые группы. Но об этом мы подробнее поговорим в другой раз.
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Sbercloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер SberCloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании SberCloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Направления
Можно стать хорошим аналитиком лишь тогда, когда человек определится с областью, в которой работать. Сегодня знают несколько видов «ученых по данным». Их разделяют по уровню трансформации на:
- инженеров – работников, которые несут ответ за целостность и оптимизацию хранения;
- разработчиков БД – отвечают за работоспособность и исправность баз информации;
- архитекторов БД – занимаются проектировкой хранения баз.
Также есть разделение по уровню обработки электронных сведений. Здесь имеет место следующее разделение на направления:
- аналитик – проводит анализ метрик, реализовывает эксперименты, составляет те или иные прогнозы;
- дата-ученый – ведет разработку продукта, который основывается на полученные сведения;
- BI-специалист – отвечает за визуализацию и интерактивные дашборды;
- ML-специалист – осуществляет разработку и несет ответственность за развитие data-driven продуктов.
Последний «работник» — это своеобразный разработчик алгоритмов. Наиболее перспективное направление, но освоить его «с нуля» весьма проблематично. Стажер не сможет создать собственный качественный проект типа data драйвен без достаточного опыта.
Какие специалисты работают с данными
Аналитик данных (Data Analyst) — работает с данными в структурированном виде из внутренних систем аналитики, помогает бизнесу суммировать и интерпретировать эти данные. Работает с Excel, SQL и внутренними системами аналитики. В SkillFactory открыт курс «Специализация Аналитик Данных»
Разработчик BI (Business Intelligence Developer) — занимается проектированием внутренних хранилищ данных, связыванием данных из различных систем, а также созданием дэшбордов и аналитических отчетов. Использует BI-системы (Oracle, IBM и другие), SQL, инструменты ETL и языки программирования.
Инженер по данным (Data Engineer) — занимается созданием и поддержкой инфраструктурой данных, в частности Big Data. Занимается сбором, хранением и управлением потоками данных в реальном времени. IT-специалист высочайшего уровня, работающий с кластерами серверов на Linux, облачными системами, такими системами обработки больших данных, как Hadoop, Spark и другие. В SkillFactory открыт курс «Специализация Data Engineer»
Специалист по данным (Data Scientist) — занимается интеллектуальным анализом структурированных и неструктурированных данных. Использует статистику, машинное обучение и продвинутые методы предиктивной аналитики для решения ключевых бизнес-задач. По сравнению с аналитиком данных, специалист по данным должен не только уметь анализировать полученную информацию, но и обладать отличными навыками программирования, уметь разрабатывать новые алгоритмы, обрабатывать большие объемы информации и иметь хорошее представление о той сфере, в которой он применяет свои знания.
Будущее Data Science
У Data Science большие перспективы, и вот почему:
Экспоненциальный рост объема данных в мире
Люди проводят все больше времени в интернете, бизнес диджитализируется, начинает развиваться интернет вещей (IoT). К 2025 году объем данных в мире увеличится почти в 3 раза, до 181 Зеттабайта (секстилиона байтов). Еще в 2010 году в мире было всего 2 Зб.
Рост рынка Data Science
Гигантские объемы данных ведут к росту количества Data Science-стартапов и вакансий специалистов по анализу данных. По прогнозам, до 2027 года рынок будет в среднем расти на 27% в год. Больше всего решений требуется в маркетинге и рекламе, логистике, финансах и поддержке пользователей.
Развитие технологий искусственного интеллекта
Эксперты утверждают, что в ближайшем будущем на улицах городов массово появятся беспилотные автомобили, а домашняя техника будет подключена к интернету вещей (IoT). Автономные автомобили используют машинное обучение для анализа дорожной ситуации и безопасного передвижения. IoT позволит получать данные миллиардов новых устройств и использовать искусственный интеллект в системах «умного дома».
Все это ведет к повышению спроса на дата-сайентистов. Так, количество вакансий в этой сфере в России за три года выросло на 433%. Спрос на специалистов превышает предложение, а это увеличивает их зарплату: junior data scientist после года обучения в среднем получает от 120 тыс. рублей, а после трех лет опыта — от 250 тыс. рублей.
Курс
Data Scientist
Специалисты Data Science нужны во всех сферах бизнеса — получите востребованную профессию и станьте одним из них. Дополнительная скидка 5% по промокоду BLOG.
Узнать больше
«Самая сексуальная профессия»
Как написал несколько лет назад журнал Harvard Business Review: «Data Scientist — самая сексуальная профессия XXI века».
В статье рассказывалось о Джонатане Голдмане, физике из Стэнфорда, который устроившись на работу в социальную сеть LinkedIn, занялся чем-то странным и непонятным. Пока команда разработчиков ломает голову над тем, как модернизировать сайт и справиться с наплывом посетителей, Голдман строит прогностическую модель, которая подсказывает владельцу аккаунта LinkedIn, кто еще из пользователей сайта может оказаться его знакомым.
С тех пор профессия Data Scientist не стала менее сексуальной, скорее наоборот. В 2016 году она возглавила кадровой компании Glassdoor. Не будем подробно останавливаться на том, почему сегодня эта профессия считается одной из самых высокооплачиваемых, привлекательных и перспективных в мире. Отметим лишь, что число вакансий в этом направлении продолжает расти по экспоненте. Согласно прогнозам McKinsey Global Institute, к 2018 году в одних только США понадобится дополнительно порядка 140-190 тысяч специалистов по работе с данными.
Неудивительно, что сегодня так много желающих освоить эту профессию. Давайте разберемся, кто же такой Data Scientist и какими навыками и знаниями он должен обладать.
Достоинства и недостатки профессии
Плюсы:
- Профессия не просто востребованная – она ощущает острую нехватку специалистов.
- Высокая заработная плата.
- Появляется чувство удовлетворения от осознания того, что приносишь пользу для компании.
- Должность сопровождается постоянным профессиональным развитием.
- Можно работать удаленно, а значит вовсе не обязательно искать работу в своем городе.
Минусы:
- Профессия не из легких и не каждый сможет ее освоить.
- Специалист часто сталкивается с проблемой, которую не решишь традиционными и уже известными методами. Поэтому ему часто приходится разрабатывать что-то новое, чтобы достичь удовлетворительного результата.
- Нужно постоянно учиться, следить за новшествами и технологиями.
Следующий шаг — полировка и углубление знаний
В машинном обучении половина успеха заключается в правильной подготовке данных для алгоритом и правильном формулировании решаемой задачи (целевой функции)
Также важно научиться проходить все шаги построения моделей машинного обучения в наиболее оптимальной последовательности. Все данные темы отлично раскрыты в курсе, записанными русскими ребятами, но на английском языке: https://www.coursera.org/learn/competitive-data-science
Не стоит обращать внимание на kaggle — приведенные методы актуальны для реальных задач. Пройдя этот курс вы сможете понять комикс ниже

В статьях сообщества ODS (см.выше) дано множество ссылок на дополнительные источники. Рекомендую с ними ознакомиться. Также, через сайт сообщества можно найти видеозаписи многих семинаров, в которых также иногда рассматриваются очень полезные и фундаментальные темы. Например, мне были полезны все выстпления от основателя сообщества, Алексея Натенкина (прогнозирование временных рядов, еще пример)
Разные смежные концепции, которые необходимо знать
Нужно четко понимать разницу между корреляцией и причино-следственной связью. Не понимая этого — нельзя работать дата-сайентистом.

С большой долей вероятности, если вы будете делать какой-нибудь сравнительный анализ различных групп (рекламных компаний, поведения людей и т.п.) вам придется столкнуться с парадоксом Симпсона (отличное видео)
Важно отточить его понимание, т.к. от его последствий необходимо защищася, и даже зная о нём, я не всегда осозновал что встречаюсь с ним в практике
Также, с точки зрения постановки целей — поведение людей часто оказывается искажено, о чём рассказывает Goodhart’s law. Знание данного эффекта может подсказать направления анализа разных явлений.
Другие полезные книги/ материалы
Куча англоязычных статей по использованию разных библиотеке, в основном очень начального уровня, регулярно публикуется на сайте https://towardsdatascience.com; до 3 статей в месяц можно читать бесплатно.
Statistics Done Wrong .The woefully complete guide by Alex Reinhart — отличная иллюстрация того как не стоит применять математические методы проверки гипотез. Автор рассказывает как даже профессиональные учёные всё время ошибаются в их использовании.
Python Machine Learning, by Sebastian Raschka — хороший набор разных кусков кода, которые могут помочь на начальном этапе. Также у этого автора хорошие статьи по разным темам.
Как находить другие хорошие книги и курсы, отбирать лучшие и наиболее подходящие — писал в предыдущих статьях.
Необходимые технические знания
Git необходимо выучить чтобы работать над каким-либо кодом совместном с другими людьми. Замечательно простая и бесплатня книжка на английском — Ry’s Git tutorial. Также много книг доступно бесплатно на официальном сайте git. Отличное визуальное объяснение разных концепций: http://ndpsoftware.com/git-cheatsheet.html
https://www.practicaldatascience.org/ — хороший набор материалов по разным библиотекам и дополнительным инструментам. Фактически, даётся исчерпывающий перечень тем, которые придётся освоить для работы в дата саенс, с вводными материалами по всем темам (секцию Cloud точо стоит читать наискосок, т.к. тут с большой вероятностью придется работать с подобными технологиями других вендоров, которые имеют отличия).
Готов выступить ментором в самообучении
Посчитав, что мой опыт самообучения и быстрый рост доказывают эффективность отобранных мной подходов, книг и курсов, я решил заняться менторством.
Если у вас есть индивидуальные вопросы, на которые не отвечают мои статьи — пишите на почту self.development.mentor в gmail.com, Олег
В результате такого общения некоторые поняли, что им лучше уйти в другую сферу (программирование, биг дата), некоторым я смог скорректировать учебный/карьерный план под индивидуальные потребности, кому-то я посоветовал тех, кто сможет помочь лучше меня, а кого-то спас (?) от неэффективной траты времени на тупиковые проекты (решение задач в машинном обучении, без понимания принципов машинного обучения).
И если мои статьи для вас полезны — на будущие статьи меня также можно мотивировать материально, под этой статьей должна быть кнопка «задонатить» для этих целей.Для получения скидок на первый месяц/курс специализаций на Coursera.org — можете воспользоваться ссылкой: http://fbuy.me/v/odemidenko
Кто он, Data Scientist?
Вообще-то Data Scientist — профессия, окруженная разными мифами. В глазах одних Data Scientists — это подобие шаманов, способных из «больших данных добывать нефть», причем знаний в области бизнеса от них не требуется. Другие причисляют к этой профессии вообще почти любого программиста: умеешь программировать — умеешь работать с данными.
Мне ближе определение, которое дает специалист по биологической статистике Джеффри Лик из Университета Джонса Хопкинса. Data Scientist — это специалист, владеющий тремя группами навыков:
- IT-грамотность — программирование, придумывание и решение алгоритмических задач, владение софтом;
- Математические и статистические знания;
- Содержательный опыт в какой-то области — понимание бизнес-запросов своей организации или задач своей отрасли науки.
Причем вакансии, подразумевающие эту специализацию, могут называться по-разному. Среди самых популярных названий — аналитик Big Data, математик или математик-программист, менеджер по анализу систем, архитектор Big Data, бизнес-аналитик, BI-аналитик, информационный аналитик, специалист Data Mining, инженер по машинному обучению и многие другие.
Кто такой Data Scientist?
Когда мы поняли, что ничего не поняли, стоит поговорить о data scientist’ах — специалистах по анализу данных.
 Data Scientist в глазах потенциального работодателя
Data Scientist в глазах потенциального работодателя
Одни считают, что эта должность подразумевает построение нейросетей в Jupyter Notebook’e. Другие ждут от таких специалистов, что те придут и будут закрывать все задачи «под ключ». А третьи просто хотят иметь в штате таких модных ребят. Такое разное понимание должности или непонимание вовсе может навредить при найме и вам, как кандидату, и компании.
Очень хорошую аналогию с Computer Science привел Валерий Бабушкин в своем докладе «Почему вы никогда не наймете дата саентиста». Постараюсь кратко ее передать.
Налицо проблема несовпадения ожиданий у кандидата и работодателя. Она в первую очередь касается неопытных ребят, которые думают, что они, наконец-то, попадут в мир Data Science, придут на работу и будут писать на уже готовеньком датасете.

Но проходит какое-то время и наступает суровая реальность: оказывается, что прежде чем обучать модели и подбирать гиперпараметры, нужно сделать очень много чего. Например, пообщаться с бизнесом и понять, какая же у них на самом деле головная боль, затем сформулировать эту боль на математическом языке, найти данные для задачи, очистить их, подумать над признаками, собрать модели, обернуть всё это в MLflow, положить в Docker-контейнер, оценить потенциальные нагрузки и отправить в эксплуатацию. Это можно сравнить с ситуацией, когда у вас спрашивают: «Ягоду будете?», вы отвечаете: «Да» и получаете арбуз — это ведь тоже ягода.