Кто такой дата-сайентист и как им стать
Содержание:
- Data Scientist: кто это и что он делает
- Уровень 1. От стажёра к джуну
- Требования к специалисту
- Этап 3. Базовые понятия и классические алгоритмы машинного обучения
- Принципы эффективного обучения
- Как решать проблему несовпадения ожиданий?
- Образование в области Data Science: ничего невозможного нет
- Быть Джуном Мидловичем, Д. С.
- Программирование: что и как учить?
- Что знают и умеют дата-сайентисты
- №1. Профессия Data Scientist PRO
Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Более 100 крутых уроков, тестов и тренажеров для развития мозга
Начать развиваться
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.
Уровень 1. От стажёра к джуну
Главное на этом уровне — научиться работать с датасетами в виде CSV-файлов, обрабатывать и визуализировать данные, понимать, что такое линейная регрессия.
Основы обработки данных
В первую очередь придётся манипулировать данными, чистить, структурировать и приводить их к единой размерности или шкале. От новичка ждут уверенной работы с библиотеками Pandas и NumPy и некоторых специальных навыков:
- импорт и экспорт данных в CSV-формате;
- очистка, предварительная подготовка, систематизация данных для анализа или построения модели;
- работа с пропущенными значениями в датасете;
- понимание принципов замены недостающих данных (импутации) и их реализация — например, замена средними или медианами;
- работа с категориальными признаками;
- разделение датасета на обучающую и тестовую части;
- нормировка данных с помощью нормализации и стандартизации;
- уменьшение объёма данных с помощью техник снижения размерности — например, метода главных компонент.
Визуализация данных
Новичок должен знать основные принципы хорошей визуализации и инструменты — в том числе Python-библиотеки matplotlib и seaborn (для R — ggplot2).
Какие компоненты нужны для правильной визуализации данных:
Данные. Прежде чем решить, как именно визуализировать данные, надо понять, к какому типу они относятся: категориальные, численные, дискретные, непрерывные, временной ряд.
Геометрия. То есть какой график вам подойдёт: диаграмма рассеяния, столбиковая диаграмма, линейный график, гистограмма, диаграмма плотности, «ящик с усами», тепловая карта.
Координаты. Нужно определить, какая из переменных будет отражена на оси x, а какая — на оси y
Это важно, особенно если у вас многомерный датасет с несколькими признаками.
Шкала. Решите, какую шкалу будете использовать: линейную, логарифмическую или другие.
Текст
Всё, что касается подписей, надписей, легенд, размера шрифта и так далее.
Этика. Убедитесь, что ваша визуализация излагает данные правдиво. Иными словами, что вы не вводите в заблуждение свою аудиторию, когда очищаете, обобщаете, преобразовываете и визуализируете данные.
Обучение с учителем: предсказание непрерывных переменных
Главное: стажёру придётся изучить методы регрессии, стать почти на ты с библиотеками scikit-learn и caret, чтобы строить модели линейной регрессии
Но чтобы стать полноценным джуниором, стажёр должен знать и уметь ещё кучу всего (осторожно — там сложные слова, но есть подсказки):
- проводить простой регрессионный анализ с помощью NumPy или Pylab;
- использовать библиотеку scikit-learn, чтобы решать задачи с множественной регрессией;
- понимать методы регуляризации: метод LASSO, метод упругой сети, метод регуляризации Тихонова;
- знать непараметрические методы регрессии: метод k-ближайших соседей и метод опорных векторов;
- понимать метрики оценок моделей регрессии: среднеквадратичная ошибка, средняя абсолютная ошибка и коэффициент детерминации R-квадрат;
- сравнивать разные модели регрессии.
Требования к специалисту
Специалист по данным неразрывно связан с Data Science – наукой о данных. Она находится на пересечении нескольких направлений: математики, статистики, информатики и экономики. Следовательно, специалисты должны понимать и интересоваться каждой из этих наук.
Кроме этого, Data Scientist должен знать:
- Языки программирования для того, чтобы писать на них код. Самые распространенные – это SAS, R, Java, C++ и Python.
- Базы данных MySQL и PostgreSQL.
- Технологии и инструменты для представления отчетов в графическом формате.
- Алгоритмы машинного и глубокого обучения, которые созданы для автоматизации повторяющихся процессов с помощью искусственного интеллекта.
- Как подготовить данные и сделать их перевод в удобный формат.
- Инструменты для работы с Big Data: Hadoop, MapReduce, Apache Hive, Apache Kafka, Apache Spark.
- Как установить закономерности и видеть логические связи в системе полученных сведений.
- Как разработать действенные бизнес-решения.
- Как извлекать нужную информацию из разных источников.
- Английский язык для чтения профессиональной литературы и общения с зарубежными клиентами.
- Как успешно внедрить программу.
- Область деятельности организации, на которую работает.
Помимо того, что специалист по данным должен обладать аналитическим и математическим складом ума, он также должен быть:
- трудолюбивым,
- настойчивым,
- скрупулезным,
- внимательным,
- усидчивым,
- целеустремленным,
- коммуникабельным.
Хочу отметить, что гуманитариям достичь высот в этой профессии будет крайне тяжело. Только при большом желании можно пробовать осваивать данную стезю.
Этап 3. Базовые понятия и классические алгоритмы машинного обучения
(Этот этап может занять 200-400 ч в зависимости от того, насколько хорошо изначально вы владеете математикой)
Базовые понятия машинного обучения:
-
Кросс-валидация
-
Overfitting
-
Регуляризация
-
Data leakage
-
Экстраполяции (понимание возможности в контексте разных алгоритмов)
Базовые алгоритмы, которые достаточно знать на уровне главных принципов:
-
Прогнозирование и классификация:
-
Линейная регрессия
-
Дерево решений
-
Логистическая регрессия
-
Random forest
-
Градиентный бустинг
-
kNN
-
-
Кластерзиация: k-means
-
Работа с временными рядами: экспоненциальное сглаживание
-
Понижение размерности: PCA
Базовые приёмы подготовки данных: dummy переменные, one-hot encoding, tf-idf
Математика:
-
умение считать вероятности: основы комбинаторики, вероятности независимых событий и условные вероятности (формула Байеса).
-
Понимать смысл фразы: «correlation does not imply causation», чтобы верно трактовать результаты моделей.
-
Мат.методы, необходимые для полного понимания, как работают ключевые модели машинного обучения: Градиентный спуск. Максимальное правдоподобие (max likelihood), понимание зачем на практике используются логарифмы (log-likelihood). Понимание как строиться целевая функция логистической регрессии (зачем log в log-odds), понимание сути логистической функции (часто называемой «сигмоид»). С одной стороны, нет жесткой необходимости всё это понять на данном этапе, т.к все алгоритмы можно использовать как черные ящики, зная только основные принципы. Но понимание математики поможет глубже понять разные модели и придать уверенности в их использовании. Позднее, для уровня senior, эти знания являются уже обязательным:
Без практических навыков знания данного этапа мало повышают ваши шансы на трудоустройство. Но значительно облегчают общение с другими дата-сайентистами и открывают путь для понимания многих дальнейших источников (книг/курсов) и позволяют начать практиковаться в их использовании.
Принципы эффективного обучения
Эффективный учебный план. Хороший план позволяет вам учить вещи в таком порядке, чтобы каждая новая вещь базировалась на уже полученных знаниях. И, в идеале, он идёт по спирали, постепенно углубляя знания во всех аспектах. Потому что учить теоретически математику, без интересных примеров применения — неэффективно. Именно это является одной из проблем плохого усваивания материалов в школе и институте.
Учебный план — это именно та вещь, которую без опыта составить труднее всего. И именно с этим я стараюсь помочь.
Следует концентрироваться на понимании главных принципов — это легче, чем запоминать отдельные детали (они часто оказываются не нужны)
Особенно важно это становится, когда вы учите язык программирования, тем более свой первый: не стоит зубрить правильное написание команд («синтаксис») или заучивать API библиотек.
Это вторая вещь, с которой я хочу помочь — разобраться, что важно, а на что не следует тратить много времени.
Как решать проблему несовпадения ожиданий?
Алексей Натекин в своем докладе «Чем отличаются data analyst, data engineer и data scientist» нарисовал картинку с распределением Дирихле, то есть с вероятностью вероятностей.

Предположим, что в Data Science существуют три основные компетенции:
-
Математика. Теоретические знания алгоритмов машинного обучения, и математическая статистика для проверки разных статистических гипотез и обработки результатов, а также любые другие фундаментальные знания, которые будут важны в вашей предметной области.
-
Разработка. Всё, что связано с разработкой, инженерными составляющими проекта, DevOps, SysOps, SRE, и прочее.
-
Предметная область. Навыки коммуникации с коллегами и бизнесом, чтобы понимать, какую проблему они хотят решить, на какие вопросы ответить.
И Data Scientist в этой парадигме — это некоторое наблюдение из нашего распределения Дирихле. Но с помощью этого распределения можно ввести несколько новых должностей, которые будут давать более ясное представление о вашей потенциальной деятельности. Рассмотрим несколько из них.
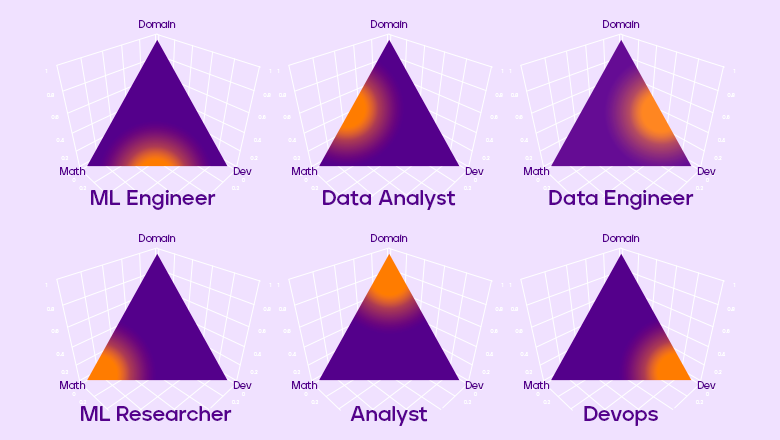
Если вы ищете работу на позицию Machine Learning Engineer, то, скорее всего, будете заниматься введением в эксплуатацию моделей машинного обучения и поддерживать их в актуальном состоянии. Для этого вам потребуются навыки и знания в области алгоритмов машинного обучения, ну и, конечно, разработки.
Если вы аналитик данных, то, вероятно, вы будете заниматься проверкой статистических гипотез, проектировать и проводить эксперименты. Для этого вам требуются фундаментальные знания математической статистики, а также необходимо держать руку на пульсе бизнеса.
Дата-инженер — это человек, который занимается ETL-процессами, архитектурой хранилища, составляет витрины и поддерживает их, организовывает потоковую обработку данных.
Machine Learning Researcher занимается исследовательской работой. Пишет и изучает статьи, придумывает новые математические методы. Таких позиций в России довольно мало, да и встречаются они, как правило, в крупных компаниях, которые могут себе это позволить.
Аналитик — это человек, который отвечает на вопросы бизнеса, и его плотность вероятности приходится на предметную область.
Наконец, DevOps максимально сосредоточен на разработке и развёртывании вашего кода в продакшене.
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.

Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Быть Джуном Мидловичем, Д. С.
Успешная работа в Data Science требует сплава знаний из программирования, статистики и консалтинга. Вот примеры задач, которые решает дата-сайентист:
- оценка потребностей заказчика;
- отбор данных для анализа;
- загрузка данных в среду разработки;
- удаление выбросов и обогащение данных;
- выбор и настройка модели;
- интерпретация результатов работы модели.
Настоящий специалист решает задачи согласованно и с учётом их взаимного влияния, а не по отдельности — «сферически в вакууме».

Эти сложные взаимосвязи рабочих задач дата-сайентиста порождают цепочки верхнеуровневых вопросов. Например:
- Как заполнить пропущенные значения в данных, исходя из особенностей бизнеса и потребностей заказчика?
- Какие параметры выбрать у моделей, если пропущенные значения заполнены тем или иным способом?
- Почему модель выдаёт странные результаты: я выбрал не те параметры, не разобрался в отрасли или просто не понял заказчика?
Программирование: что и как учить?
Что такое SQL и зачем его учить?
SQL является стандартом для получения данных в нужном виде из разных баз данных. Это тоже своеобразный язык программирования, который дополнительно к своему основному языку используют многие программисты. Большинство самых разных баз данных использует один и тот же язык с относительно небольшими вариациями.
SQL простой, потому что он «декларативный»: нужно точно описать «запрос» как должен выглядеть финальный результат, и всё! — база данных сама покажет вам данные в нужной форме. В обычных «императивных» языках программирования нужно описывать шаги, как вы хотите чтобы компьютер выполнил вашу инструкцию. C SQL намного легче, потому что достаточно только точно понять что вы хотите получить на выходе.
Сам язык программирования — это ограниченный набор команд.
Когда вы будете работать с данными — даже аналитиком, даже необязательно со знанием data science, — самой первой задачей всегда будет получить данные из базы данных. Поэтому SQL надо знать всем. Даже веб-аналитики и маркетологи зачастую его используют.
Как учить SQL:
Наберите в Гугле «sql tutorial» и начните учиться по первой же ссылке. Если она вдруг окажется платной, выберете другую. По SQL полно качественных бесплатных курсов.
На русском языке тоже полно курсов. Выбирайте бесплатные.
Главное — выбирайте курсы, в которых вы можете сразу начать прямо в браузере пробовать писать простейшие запросы к данным. Только так, тренируясь на разных примерах, действительно можно выучить SQL.
На изучение достаточно всего лишь от 10 часов (общее понимание), до 20 часов (уверенное владение большей частью всего необходимого).
Почему именно Python?
В первую очередь, зачем учить Python. Возможно, вы слышали что R (другой популярный язык программирования) тоже умеет очень многое, и это действительно так. Но Python намного универсальнее. Мало сфер и мест работы, где Python вам не сможет заменить R, но в большинстве компаний, где Data Science можно делать с помощью Python, у вас возникнут проблемы при попытке использования R. Поэтому — точно учите Python. Если вы где-то услышите другое мнение, скорее всего, оно устарело на несколько лет (в 2015г было совершенно неясно какой язык перспективнее, но сейчас это уже очевидно).
У всех других языков программирования какие-либо специализированные библиотеки для машинного обучения есть только в зачаточном состоянии.
Как учить Python
Основы:
Прочитать основы и пройти все упражнения с этого сайта можно за 5-40 часов, в зависимости от вашего предыдущего опыта.
После этого варианты (все эти книги есть и на русском):
-
Learning Python, by Mark Lutz (5 издание). Существует и на русском.
Есть много книг, которые сразу обучают использованию языка в практических задачах, но не дают полного представления о детальных возможностях языка.
Эта книга, наоборот, разбирает Python досконально. Поэтому по началу её чтение будет идти медленнее, чем аналоги. Но зато, прочтя её, вы будете способны разобраться во всём.
Я прочёл её почти целиком в поездах в метро за месяц. А потом сразу был готов писать целые программы, потому что самые основы были заложены в pythontutor.ru, а эта книга детально разжевывает всё.
В качестве практики берите, что угодно, когда дочитаете эту книгу до 32 главы, и решайте реальные примеры (кстати, главы 21-31 не надо стараться с первого раза запоминать детально. Просто пробежите глазами, чтобы вы понимали что вообще Python умеет).
Не надо эту книгу (и никакую другую) стараться вызубрить и запомнить все детали сразу. Просто позже держите её под рукой и обращайтесь к ней при необходимости.
Прочитав эту книгу, и придя на первую работу с кучей опытных коллег, я обнаружил, что некоторые вещи знаю лучше них.
-
Python Crash Course, by Eric Matthes
Эта книга проще написана и отсеивает те вещи, которые всё-таки реже используются. Если вы не претендуете быстрее стать высоко-классным знатоком Python — её будет достаточно.
-
Automate the Boring Stuff with Python
Книга хороша примерами того, что можно делать с помощью Python. Рекомендую просмотреть их все, т.к. они уже похожи на реальные задачи, с которыми приходится сталкиваться на практике, в том числе специалисту по анализу данных.
Какие трудозатраты?
Путь с нуля до уровня владения Python, на котором я что-то уже мог, занял порядка 100ч. Через 200ч я уже чувствовал себя уверенно и мог работать над проектом вместе с коллегами.
(есть бесплатные программы — трекеры времени, некоторым это помогает для самоконтроля)
Что знают и умеют дата-сайентисты
Вот начальный список навыков, знаний и умений, которые нужны любому дата-сайентисту для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое.
Есть те, кто говорит, что это всё не нужно, и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну, вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Мы уже писали, что Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
R и статистика в действии. Картинка с Хабра.
Умение получать и визуализировать данные. Не всем дата-сайентистам везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего они сами должны выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Второй важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
№1. Профессия Data Scientist PRO
Платформа обучения: Образовательный онлайн-сервис Skillbox.
Кому подойдет: Новичкам, решившим с нуля освоить Python и SQL, научиться собирать и анализировать данные и выбрать профессию в IT-сфере. Даже у тех, кто ранее не связывался с программированием, появится шанс пройти стажировку еще во время обучения.
Программистам, мечтающим вновь подтянуть математику и статистику, настроиться на аналитическое и алгоритмическое мышление, научиться выявлять потребности бизнеса, применять Python и повысить заработную плату.
Аналитикам с опытам, заинтересованным в смене специальности: даже новички научатся писать эффективный код на Python, разбираться в математике и иных тонкостях, связанных с аналитикой данных.
Длительность курса: Зависит от выбранной специальности. Доступно обучение по профессиям Machine Learning, «Дата-инженер» и «Аналитик данных». Каждый студент пройдет более 15 онлайн-курсов и преодолеет более 100 часов практических испытаний.
Сертификат или диплом: Да, диплом о профессиональной переподготовке государственного образца по выбранной специальности. Выдается студентам и электронный сертификат, закрепляемый в личном кабинете.
Трудоустройство: Гарантированная помощь с трудоустройством и прохождением стажировки в качестве Junior-специалиста. Дополнительно предусмотрены консультации, связанные с оформлением портфолио.
Стоимость курса: Рассрочка без первого взноса с ежемесячным платежом от 5 900 рублей. Без скидки – от 9 834 рублей.
Чему научитесь:
- Анализировать объемную информацию, создавать модели прогнозирования в бизнесе, медицине, промышленности;
- Обучать нейронные сети, подготавливать аналитические системы и рекомендательные сервисы;
- Развиваться в сфере обработке естественного языка или Computer Vision;
- Разворачивать инфраструктуру для организации сбора и обработки данных;
- Генерировать отказоустойчивые системы для работы с Big Data;
- Писать код на Python, оформлять SQL-запросы, искать и исправлять ошибки;
- Собирать и анализировать информацию, выискивать закономерности, строить гипотезы.
Как проходит обучение: Основа учебного курса – вебинары, транслируемые в режиме реального времени или добавляемые в личный кабинет в записи. После каждого занятия – практические испытания, разбираемые вместе с наставником. Финальный этап – обязательная защита диплома.
Преподаватели: Авторы профессии – Кирилл Шмидт и Юлдуз Фаттахова. Дополнительно лекции ведут действующие специалисты в рамках Data Engineer и Machine Learning, а вместе с тем – программисты и студенты-выпускники Skillbox.
Преимущества курса:
- Скидки для студентов Skillbox, оплата обучения в рассрочку, возможность не платить за первые 3 месяца доступа к лекциям, практическим испытаниям и дополнительным материалам;
- Наличие индивидуальной карьерной консультации, сосредоточенной вокруг подготовки резюме и оформления портфолио, прохождения собеседований и поиска вакансий;
- Доступ к бонусным курсам: «Карьера разработчика: трудоустройство и развитие», «Система контроля версий Git», «Английский для IT-специалистов»;
- Год обучения английскому языку вместе с онлайн-школой «КЭСПА» в подарок: предложение включает 4 индивидуальные сессии с преподавателем по 25 минут;
- Возможность выбрать подходящую специальность на основе пройденного материала и добраться до позиции Middle;
- Серия обязательных дипломных проектов, проверяющих знания и способных дополнить портфолио и стать дополнительным аргументом при трудоустройстве;
- Шанс зарегистрироваться и стать частью платформы Kaggle, публикующей задания для отработки навыков на реальных рабочих кейсах;
- Курс адаптирован под новичков, совмещающих обучение – с работой или учебой: для прохождения заданий достаточно от 3 до 7 часов в неделю;
- Почти круглосуточная помощь от кураторов, преподавателей и координаторов.